
🙏 श्रीमान् वेङ्कटनाथार्यः कवितार्किक केसरी । वेदान्ताचार्य वर्यो मे सन्निधत्तां सदा हृदि ॥ 🙏
About TT28
TT28 is a phonics-based transliteration-oriented publisher tool. It runs inside Microsoft Office Document Framework and Processor environment. It transliterates a prepared text document from any source language to 28 languages using a simple, standard phonics-based encoding scheme.
Architecture: The following diagram depicts the current architecture and processes around the transliteration methodology.
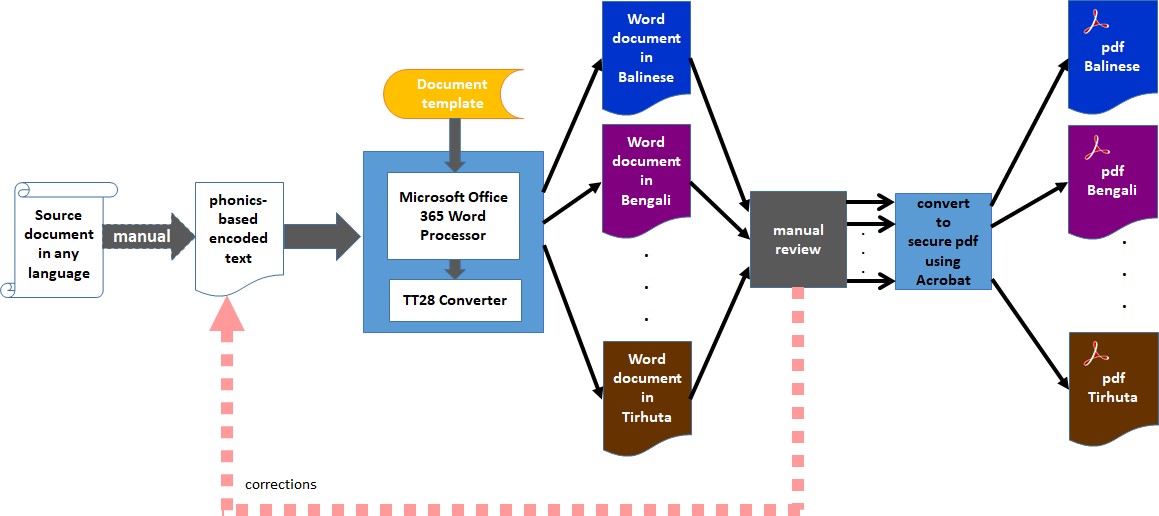
A source document is prepared based on phonics. This requires a lot of discipline. The encoding rules have been standardized to ensure language-specific transliteration occur with the words having the correct sequence of consonants/consonant clusters and the correct vowels all in the right places that guarantees the phonic identity of words between the source language and each of the target languages.
The transliteration logic relies on the Unicode character encoding system. All TT28 does is generate the corresponding sequence of Unicode characters for each target language using the same source document. A language font that is built based on Unicode then actually presents the Unicode-encoded sequences of bytes together into language-specific characters.
The initial set of 28 languages we selected as part of TT28 tool was based on two important criteria
- Proximity of the target language relative to Sanskrit from an alphabet set and a phonics standpoint
- Not all languages come with the same phonic alphabet set but many have a ‘Nukta’ character (aka consonant modifier) as part of their character sets to help represent foreign characters. For example Bengali Unicode set has a Nukta character. Hence,this would help say represent ‘zha’ consonant (in Tamil) with ‘y’ in Bengali in conjunction with the Nukta. If a language does not have a Nukta character, then TT28 provides a standard right-arrow symbol ‘>’ as a Nukta equivalent and is always shown as a subscript in red color to the right of the consonant.
- After reviewing and testing the use of Nukta character in the Unicode representation, we realized that the Nukta is only a consonant modifier and it cannot be used as a vowel modifier. Where needed, TT28 provides a standard left-arrow symbol ‘<’ as a vowel modifier and is always shown as a superscript in red color to the left of the vowel-consonant. Please note TT28’s vowel modifier will break the consonant clustering and apply to the right most consonant to which the vowel is associated. This is not an issue per se as ‘virama’ will automatically apply to the preceding consonant/consonant cluster.
- Target language must have a Unicode-based font
- TT28 implementation is based on Unicode and hence a language having a font based on Unicode is mandatory. We chose
- languages that have Unicode fonts in the standard Microsoft Office product,
- languages that have downloadable Unicode fonts freely available in the public domain for non-commercial use,
- a few languages using Google’s ‘Noto’ fonts, and lastly
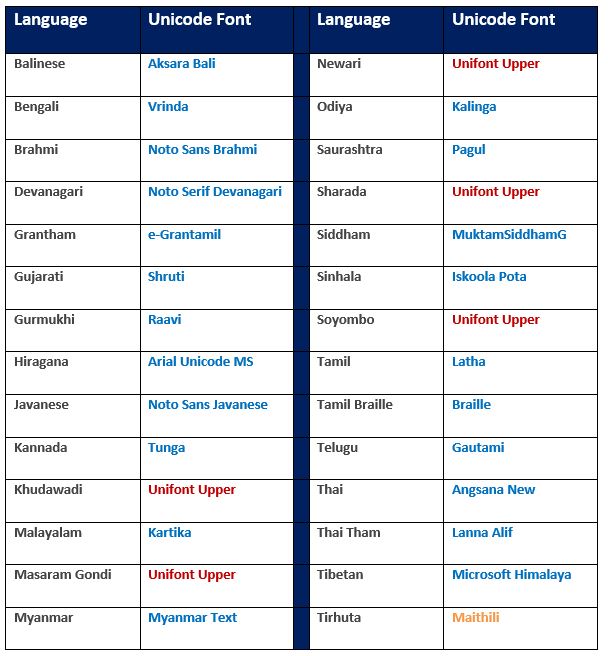
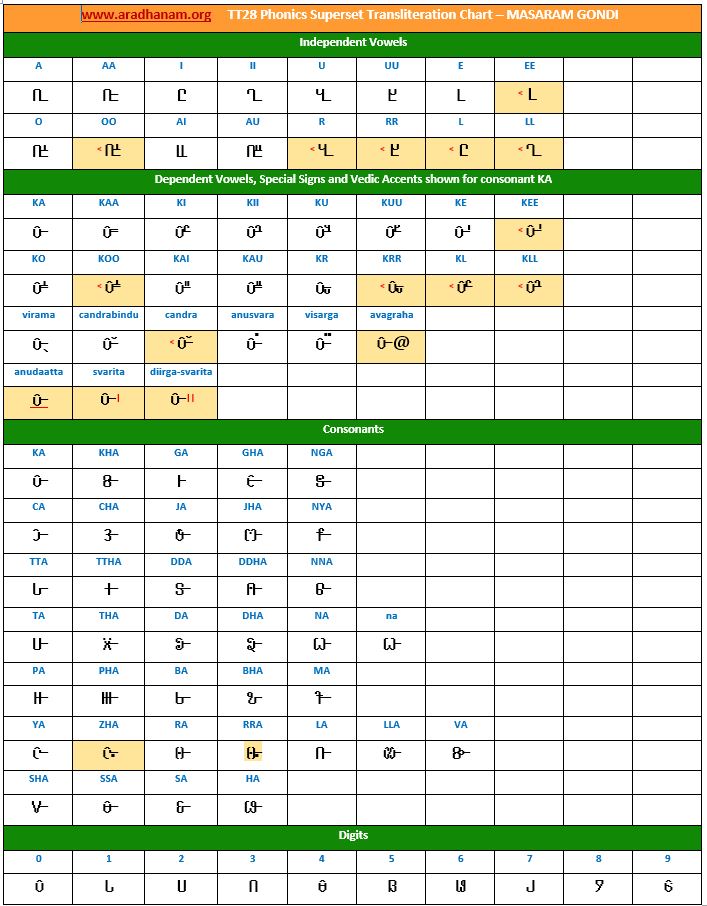
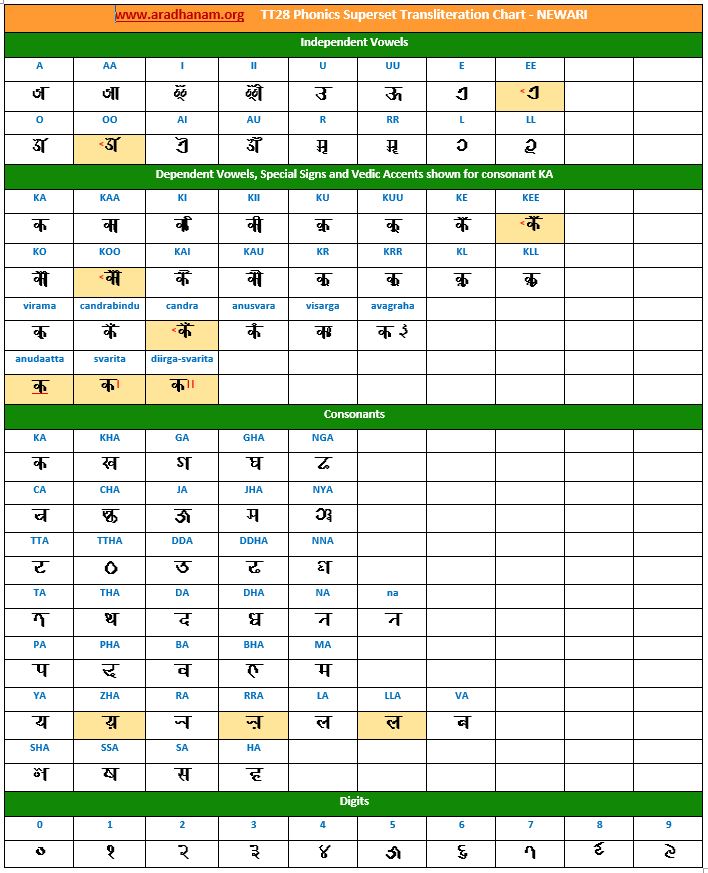
- ‘Unifont Upper’ font for 5 languages that are in the Unicode Plane 1 (aka – SMP which stands for Supplementary Multilingual Plane). They are Khudawadi, Masaram Gondi, Newari, Sharada, and Soyombo. The Unifont Upper font does not seem to have the finesse, smoothness and sharpness like the commercial fonts have. If and when we find nice Unicode fonts or say, if Google extends its NoTo set of fonts to include these languages, then we will definitely replace the Unifont Upper font and re-publish the documents for these 5 languages mentioned above.
- TT28 implementation is based on Unicode and hence a language having a font based on Unicode is mandatory. We chose
The font used for each language is listed in a table down below in a separate section.
Languages: The 28 languages are as grouped as follows
- Major Indian languages: Bengali, Devanagari, Gujarati, Gurmukhi, Kannada, Malayalam, Odiya, Tamil, and Telugu
- Minor Indian languages: Grantham, Khudwadi, Masaram Gondi, Sharada, Saurashtra, and Tirhuta
- Foreign languages: Balinese, Hiragana, Javanese, Myanmar, Newari, Siddham, Sinhala, Soyombo, Thai, Thai Tham and Tibetan
- Historical language: Brahmi
- Language for the visually impaired: Tamil Braille
The large icons used for the languages are as follows –

Fonts: The following Unicode fonts have been used to generate the documents. This is just for your information. Please note that these fonts are not needed in your computer/device since, as readers, you will be simply using a secure, prepackaged pdf document to read/print. No font download is necessary.
Language Notes: Some salient notes are given below.
- What transliteration is about: Transliteration is only about phonics-based, literal translation of a word i.e. how the word is said in the source language. An example between Sanskrit and Tamil is given below.
- स्वामी (Sanskrit source) to ஸ்வாமீ (Tamil target) and likewise
- ஸ்வாமி (Tamil source) to स्वामि (Sanskrit target)
- Encoding rules will properly transliterate the Tamil word “மூர்த்தி” to Devanagari word “मूर्ति” and not “मूर्त्ति” and vice-versa.
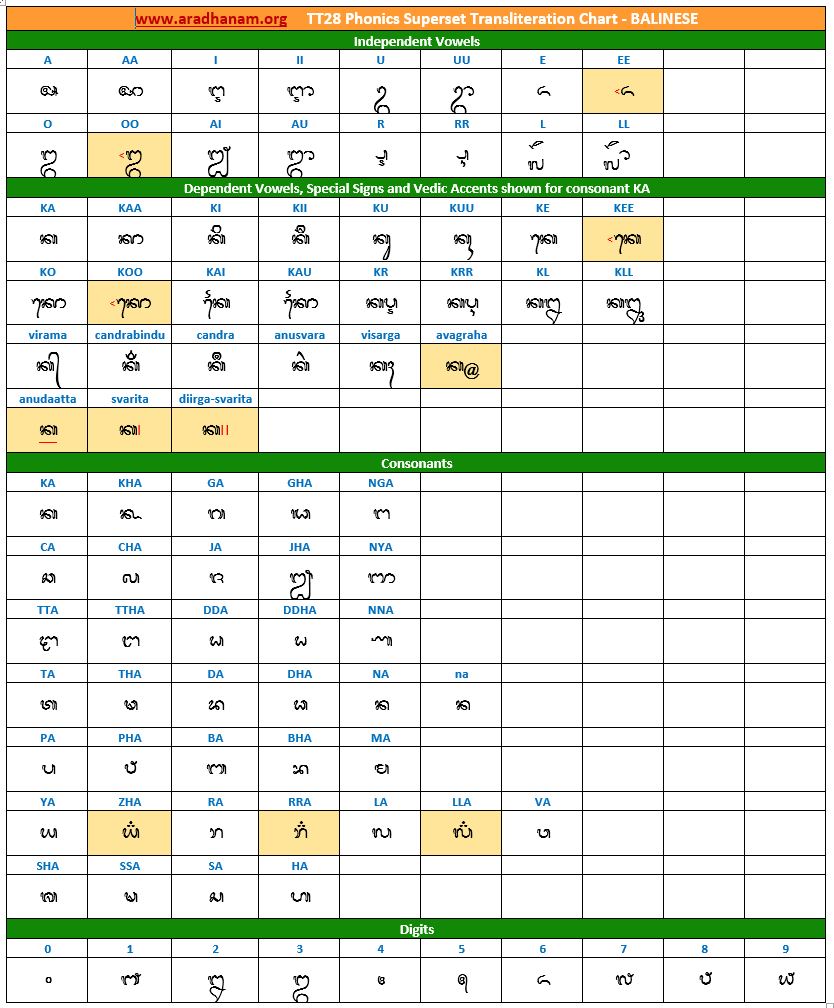
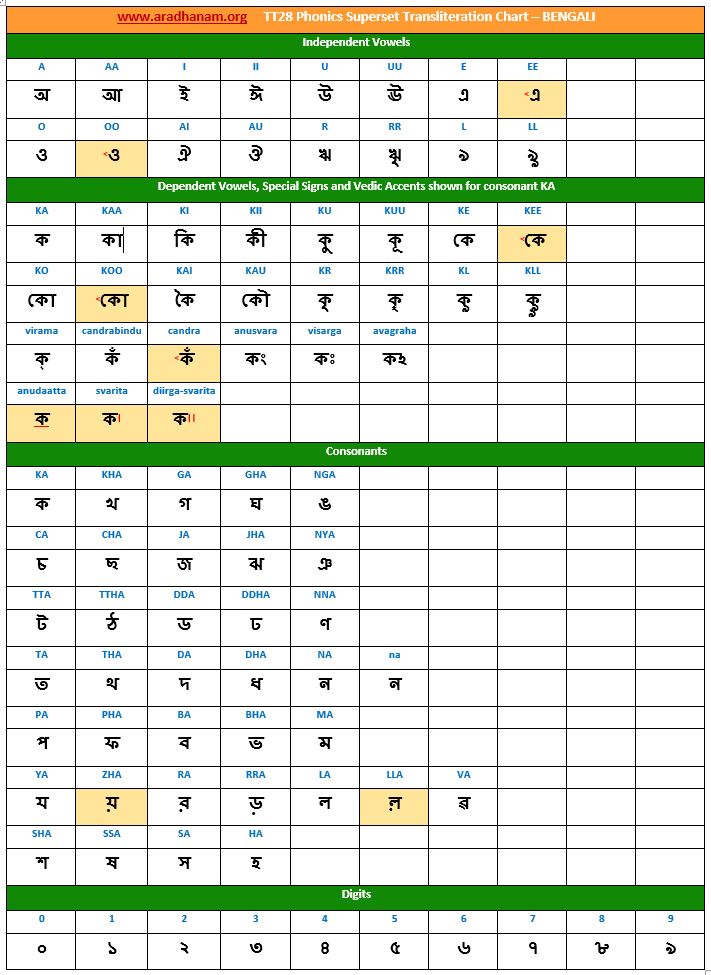
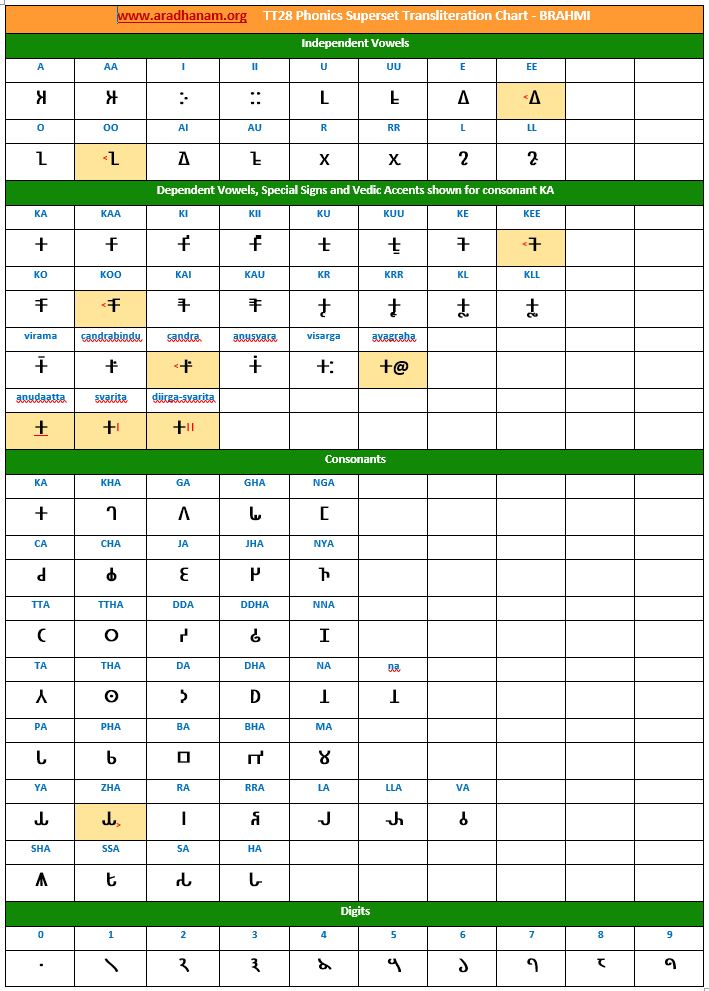
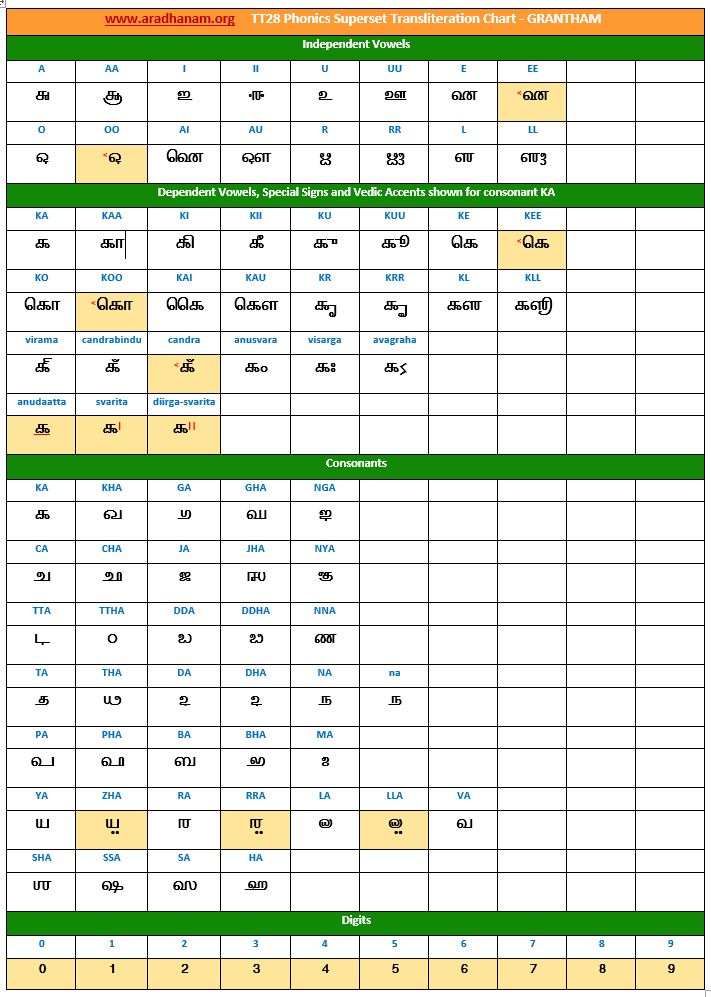
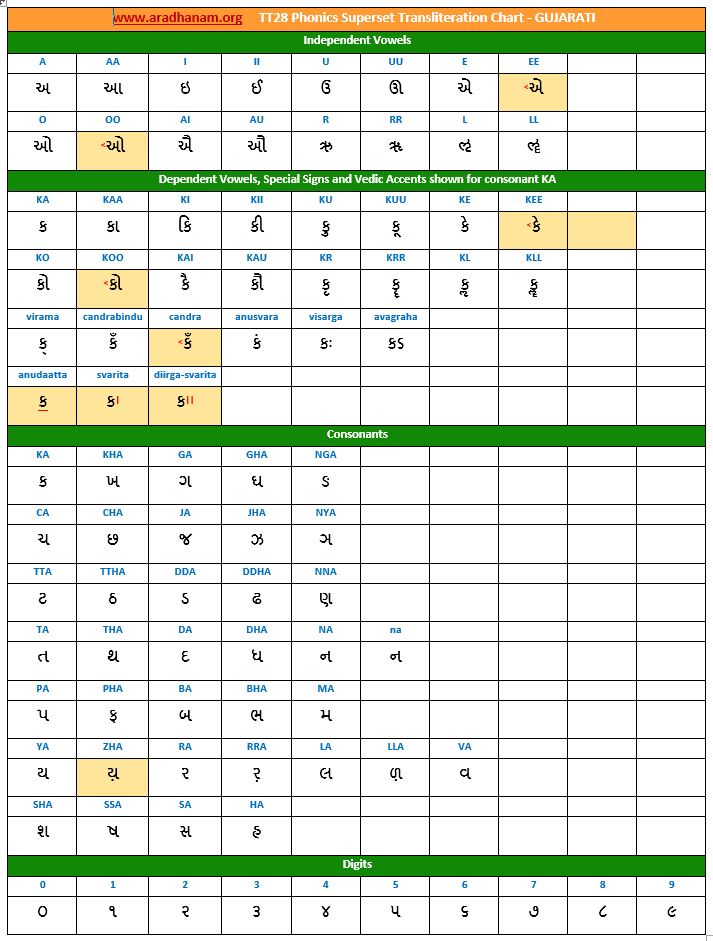
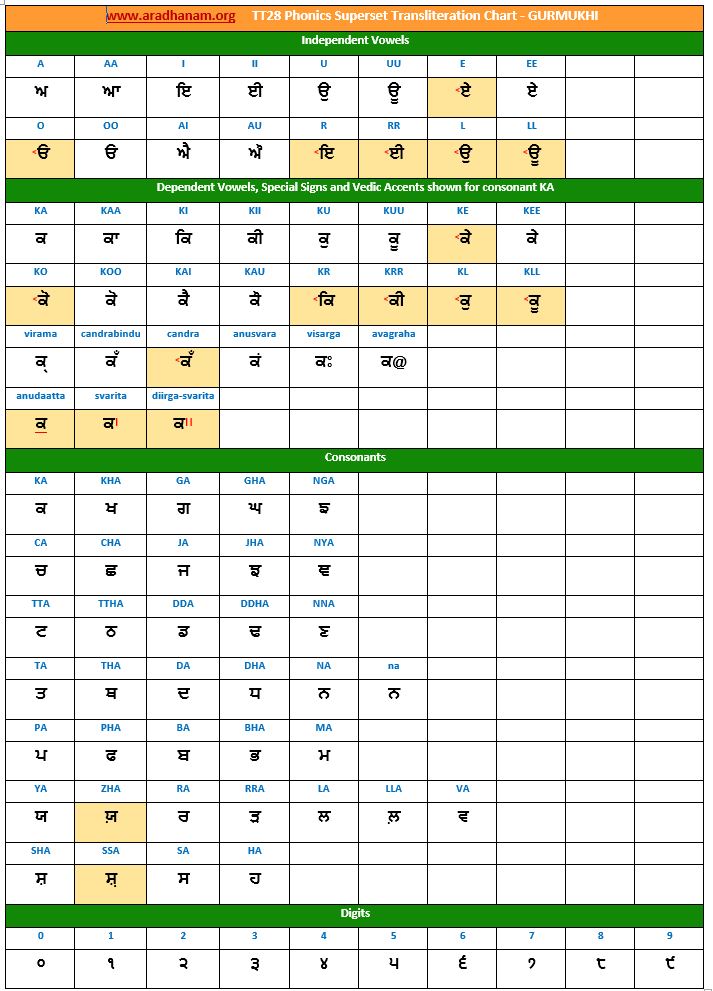
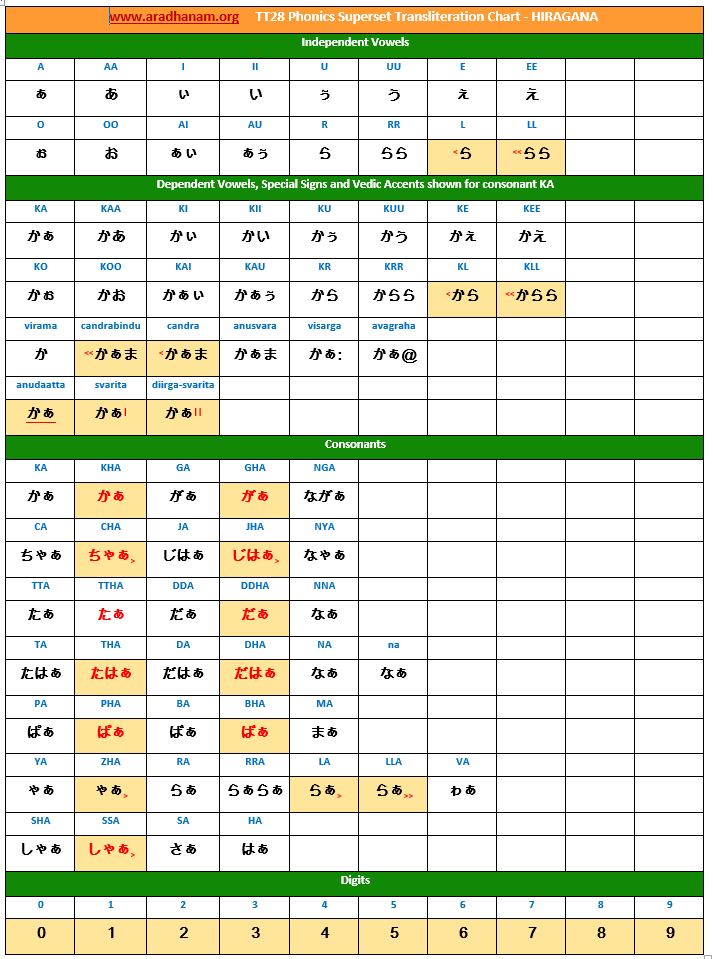
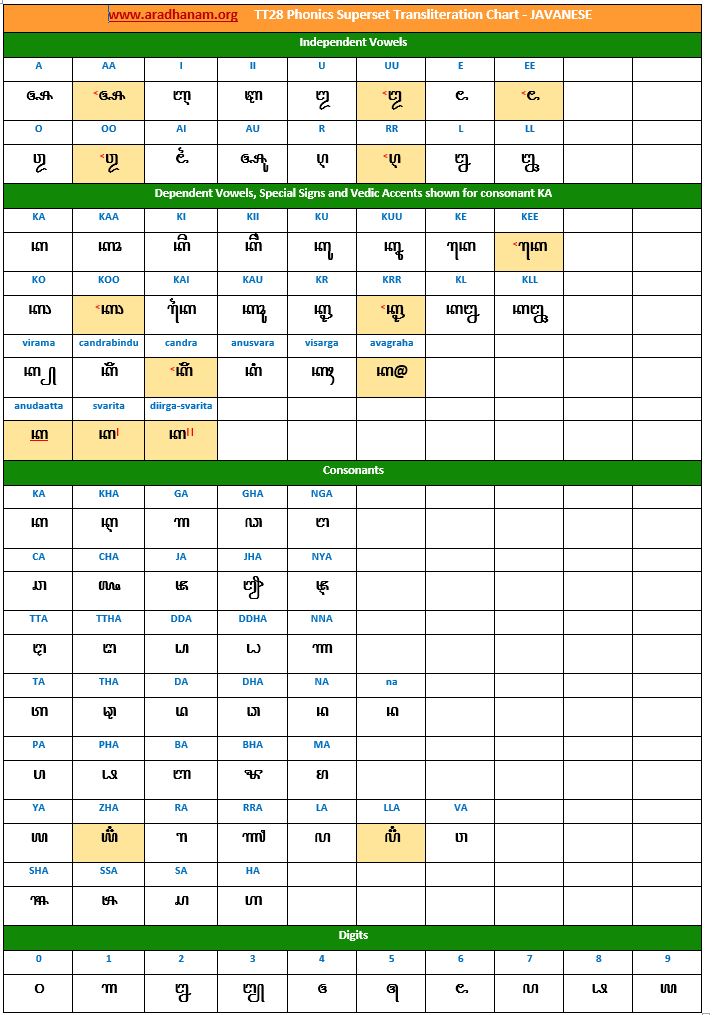
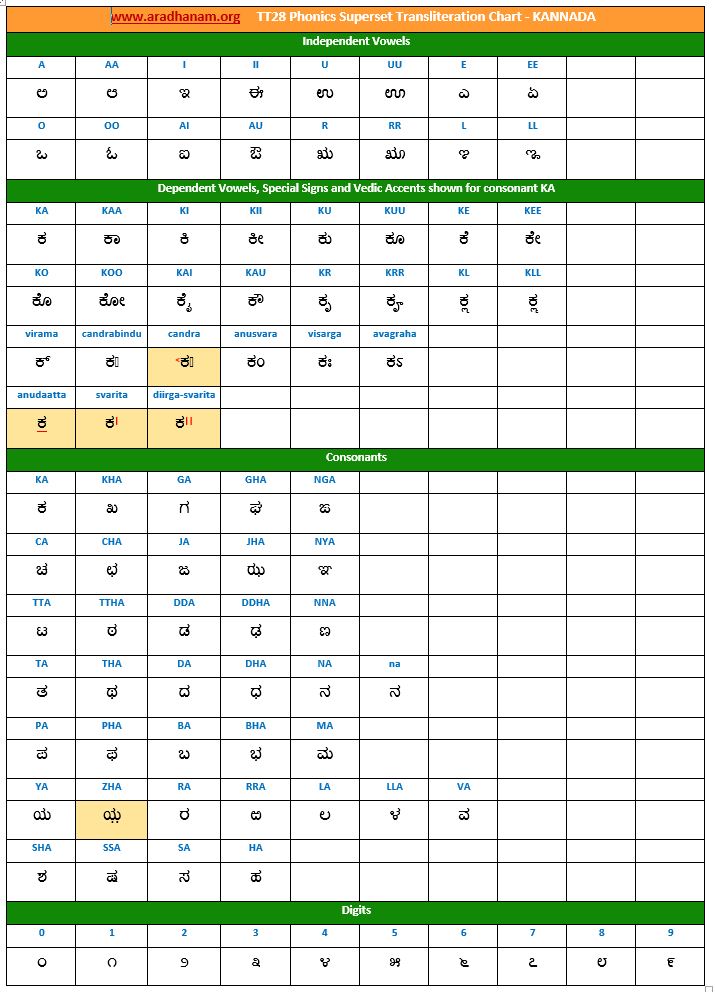
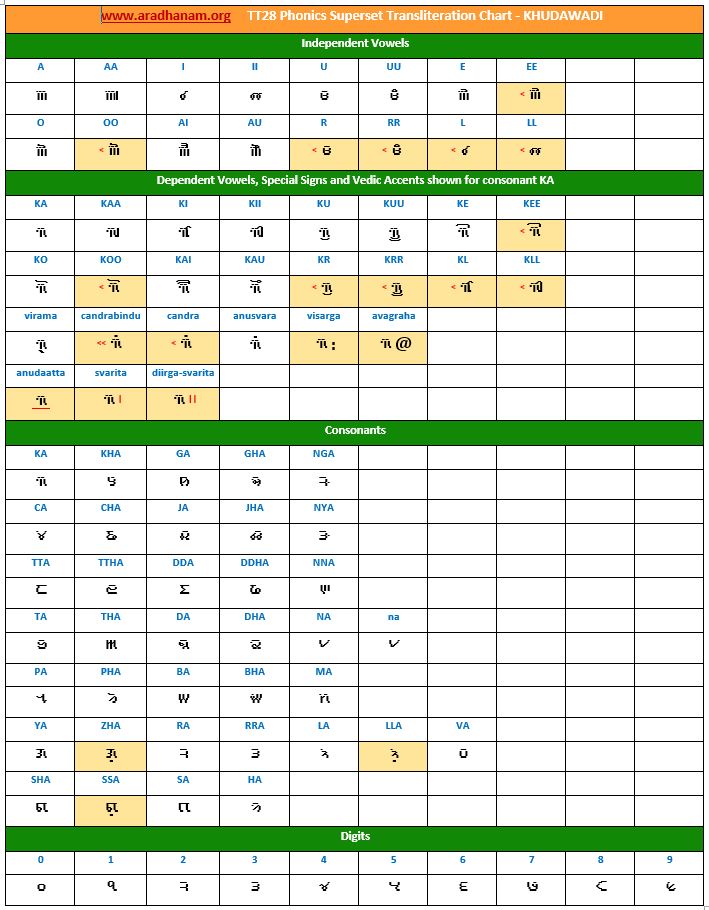
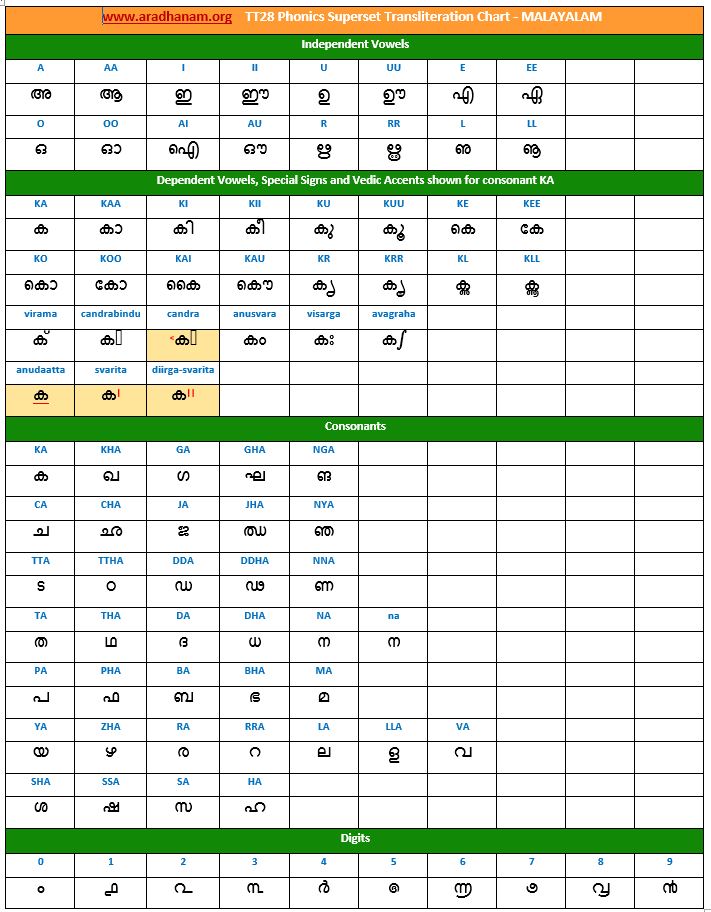
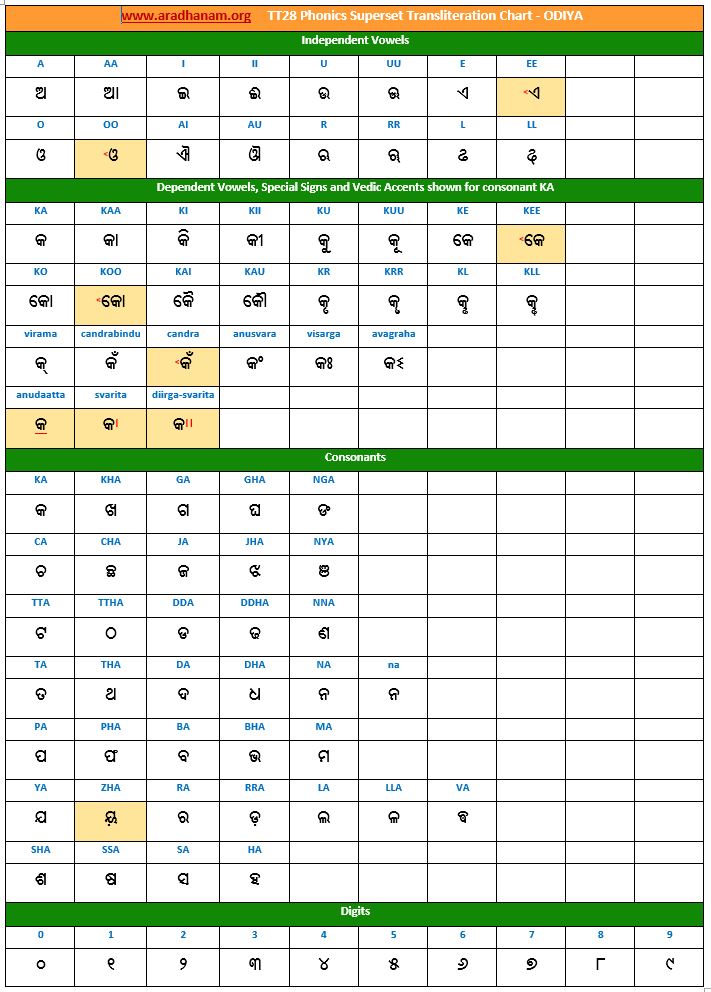
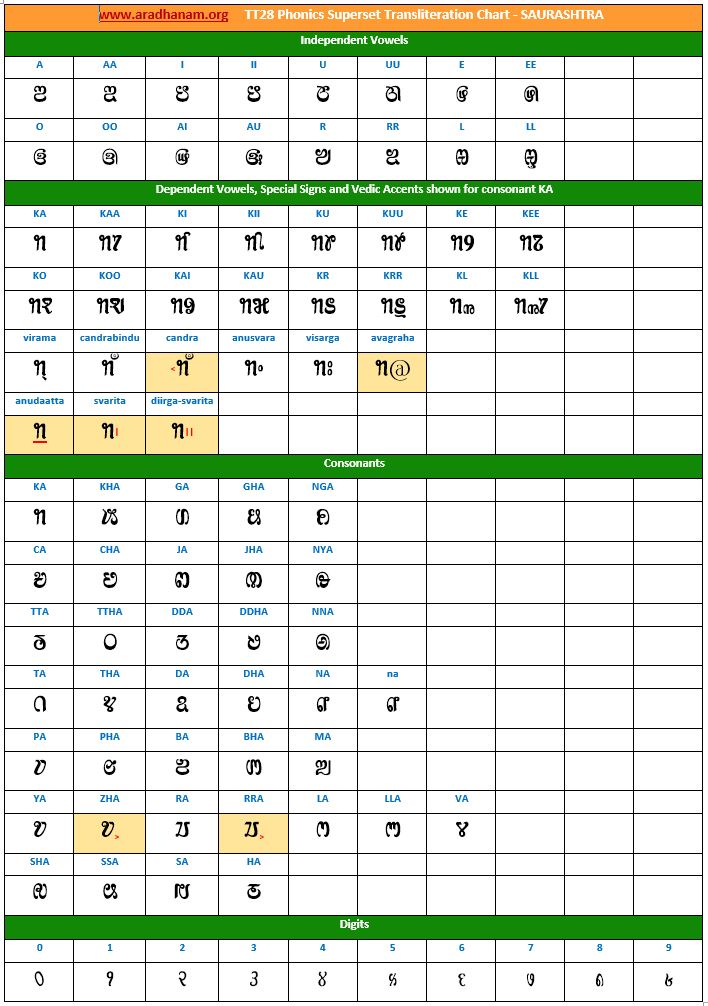
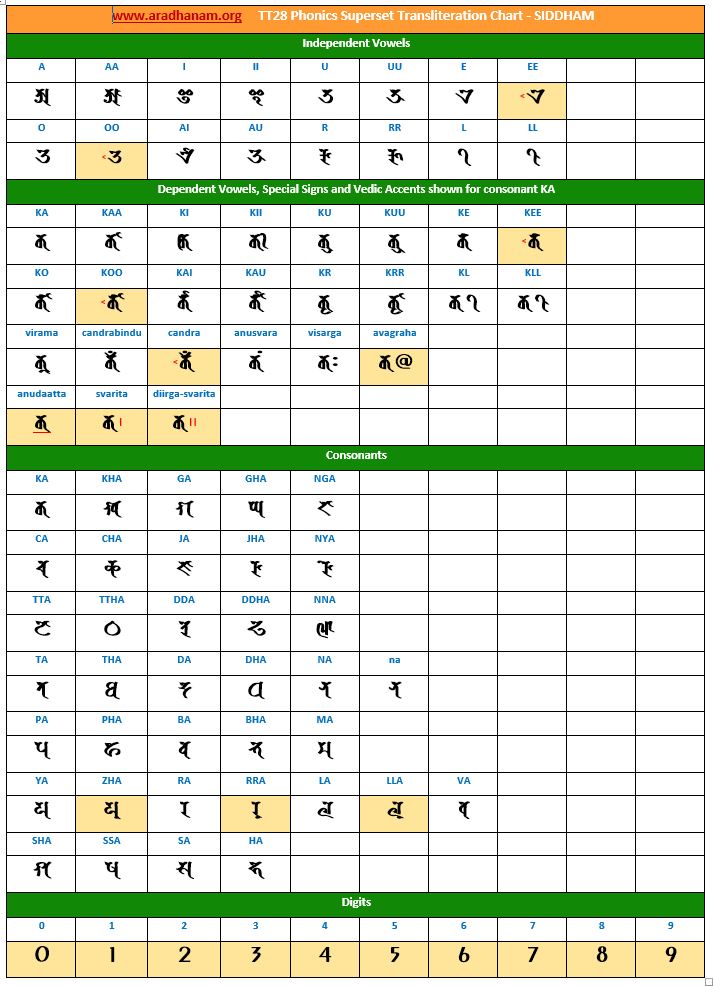
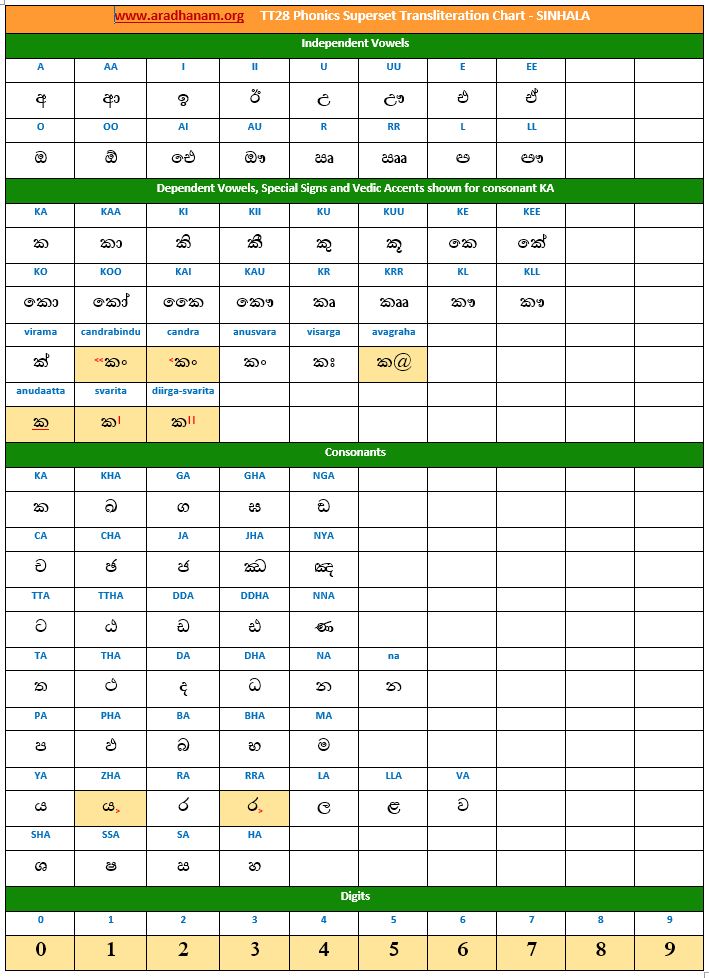
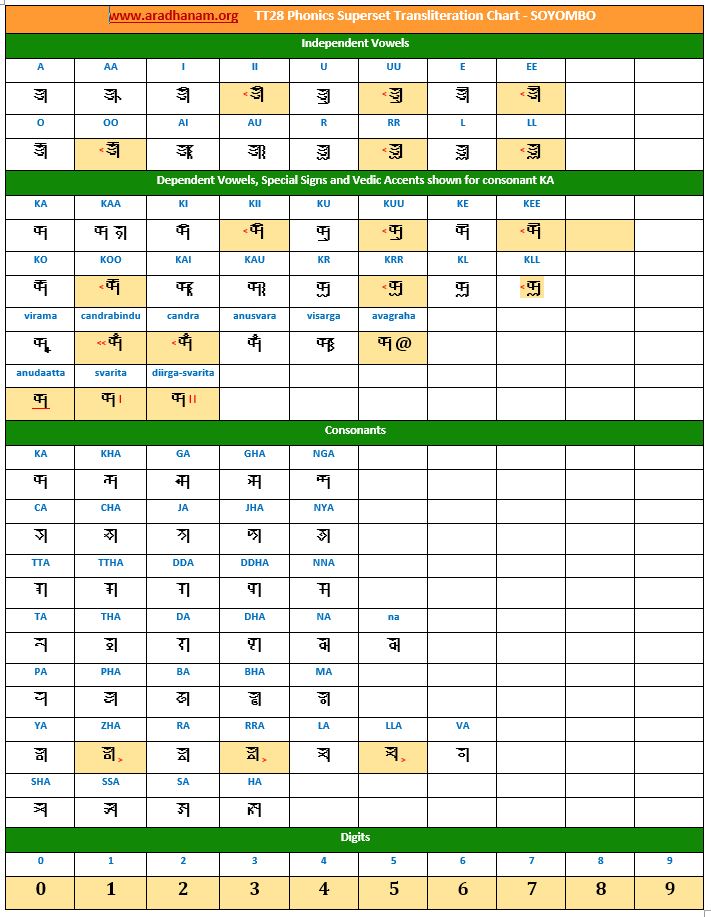
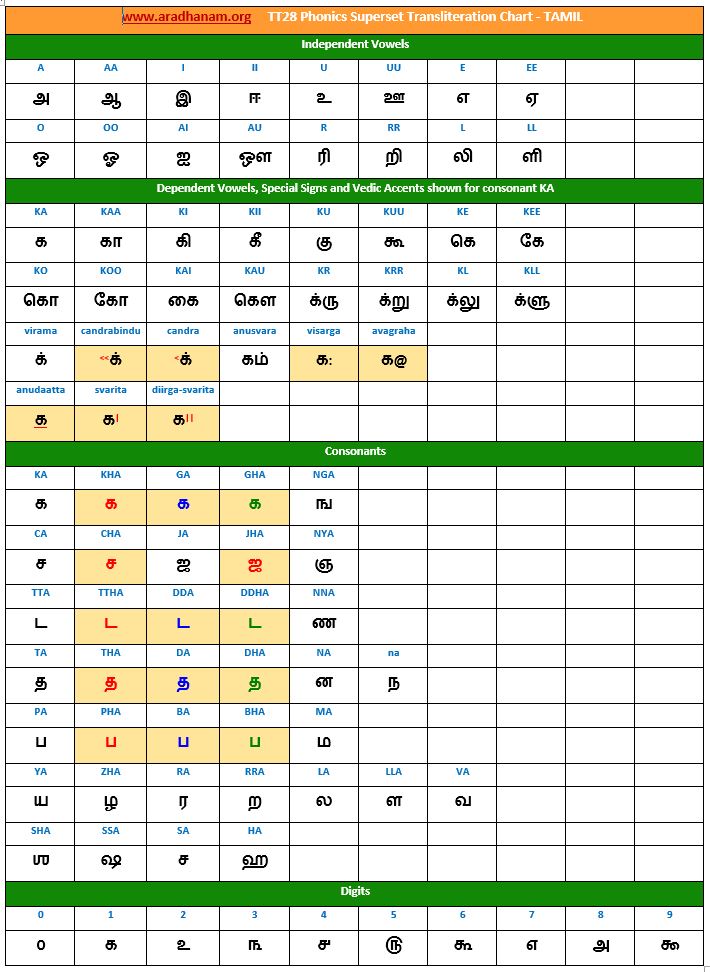
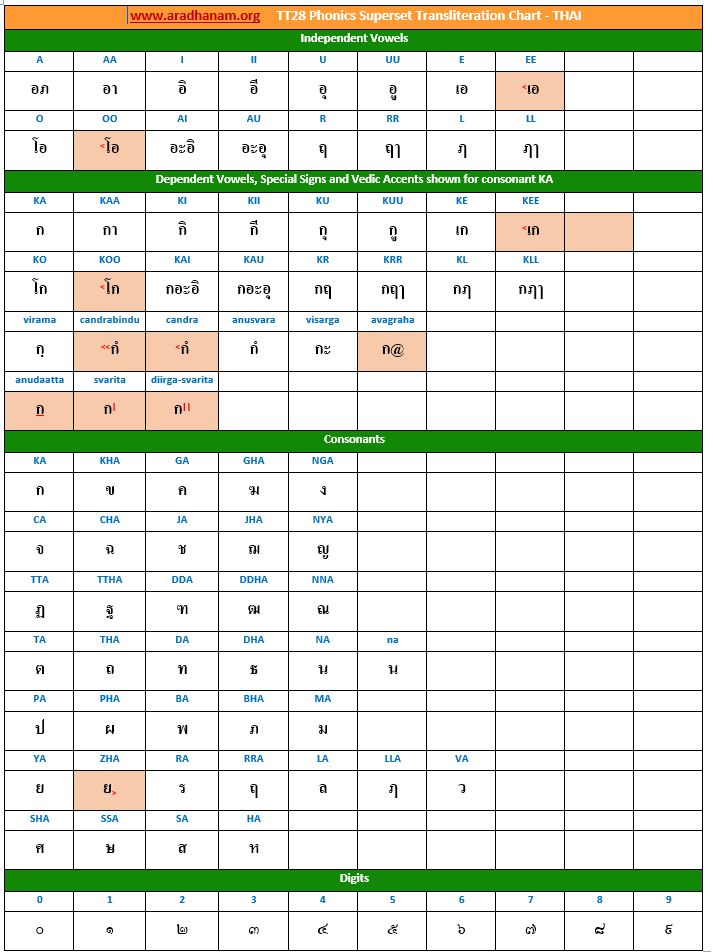
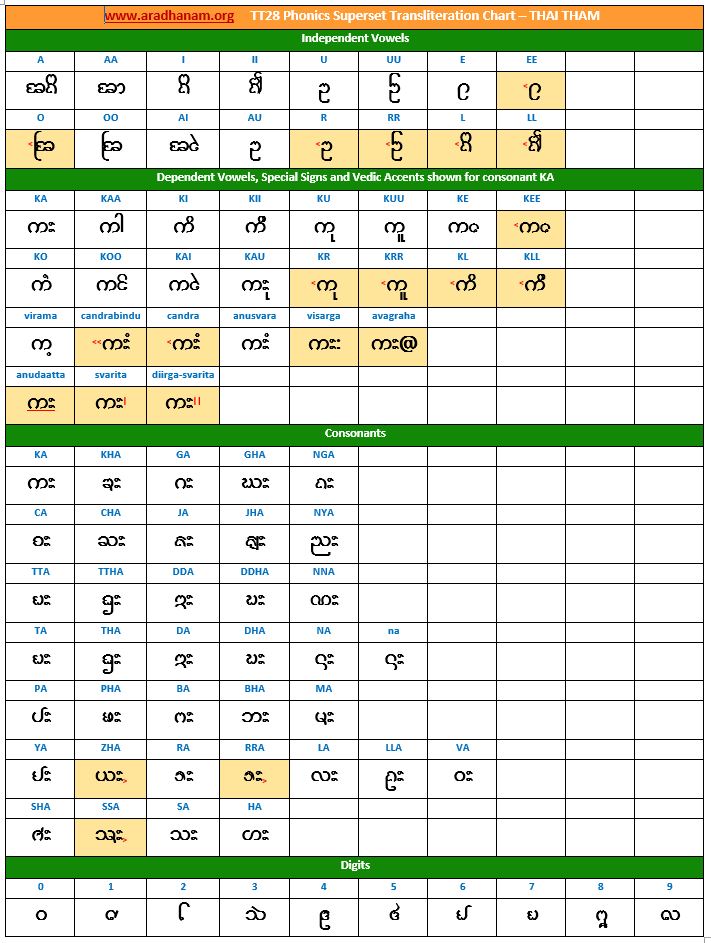
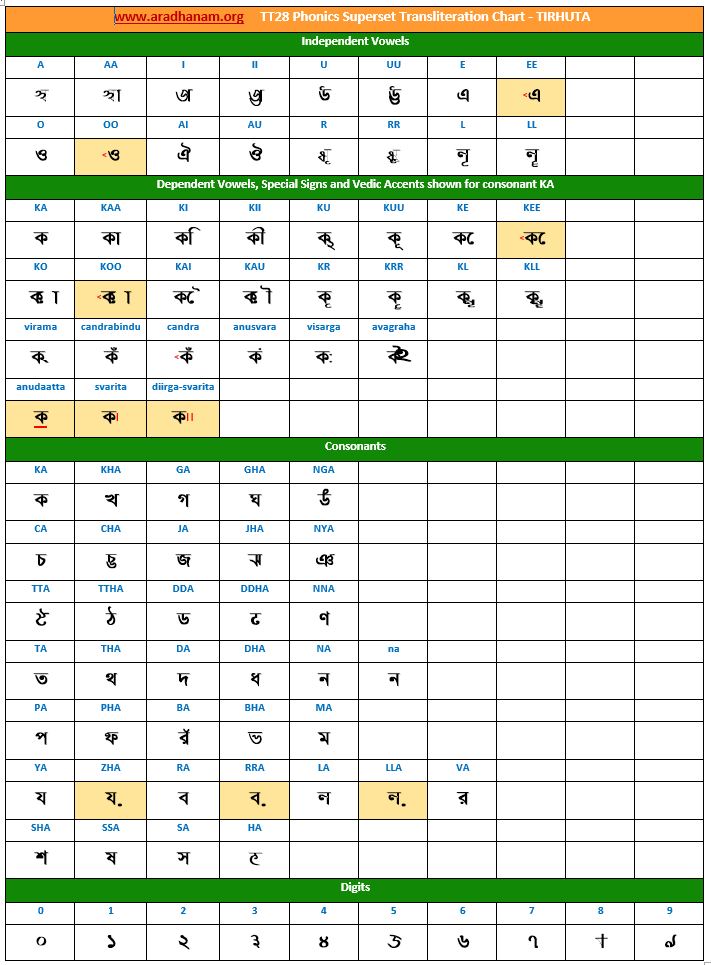
- Each chart has the same set of phonics super-set for transliteration purposes in 4 sections
- set of independent vowels,
- set of dependent vowels, special signs and Vedic accents shown for consonant ‘ka’,
- classified set of consonants and
- digits
This is the set we thought we require on a minimal basis and to get started. We will expand this set later if needed.
- The ‘zha’ common to Tamil (ழ ) and Malayalam (ഴ) is included in the consonant set. Please check the following Google link and click on on the ‘audio’ button on the left bottom corner to hear how it is uttered.
How to pronounce ‘zha’ in Tamil and Malayalam
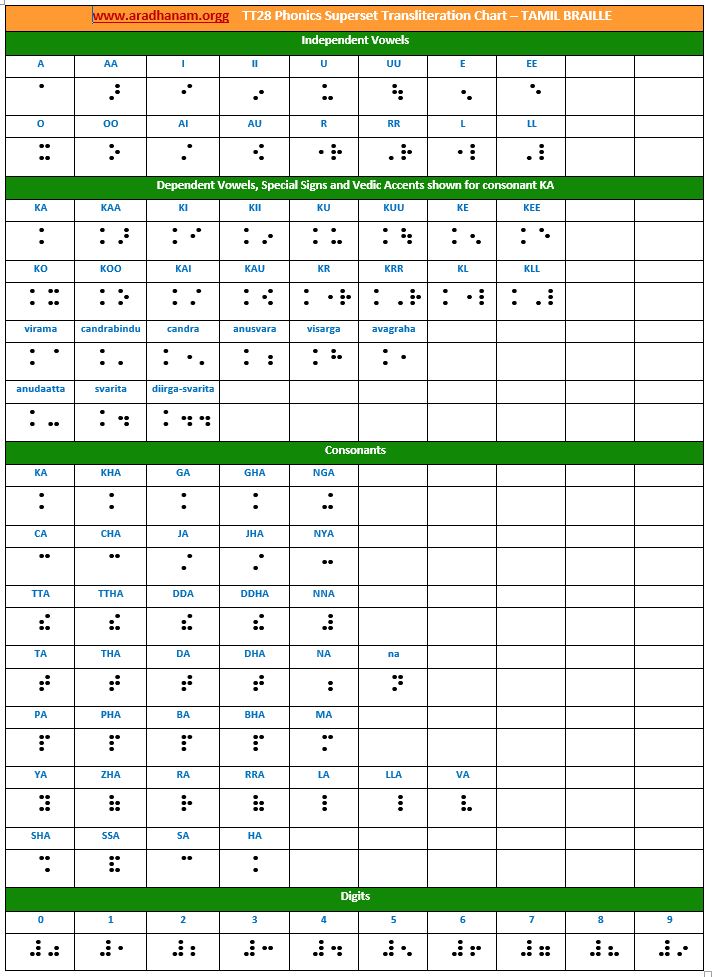
- You can think of our use of TamilBraille as a combination of the standard Tamil Braille for the Tamil alphabet and an extension into Bharathi Braille for special characters. The following 2 online sources were used our transliteration purposes
https://www.wikiwand.com/en/Tamil_Braille
https://www.wikiwand.com/en/Bharati_Braille
Research into Braille documentation rules and standards may not be complete. We welcome any expert guidance and help.
- For Vedic texts, the following have been standardized across 27 languages (except Braille)
- anudaatta (red color underline)
- svarita ( a single superscripted ascii vertical character | )
- diirga-svarita ( two superscripted ascii vertical characters || )
- visarga ( : ) dispensed wih language-specific visarga and we have used ascii ‘:’ instead
- A cell in a chart (please see links to language charts below) is highlighted in YELLOW color for one of the following reasons
- Corresponding vowel/consonant/special sign/digit is not native to the language. In this case, you will notice the presence of a TT28 vowel nukta or a native language consonant nukta or a TT28 consonant nukta.
- A special sign like visarga/avagraha, etc is missing in the native alphabet set and a standard TT28 sign is substituted in place.
- In Tamil language, the same ‘ka’ consonant is used to represent ‘ka’, ‘kha’, ‘ga’, ‘gha’. Instead of using the numeric suffix notation, we have followed a much more embedded and subtler technique based on standard color coding scheme. For the same ‘ka’ consonant,
- ‘க‘representing ‘ka’ (native, primary, un-aspirated sound) is always shown in BLACK color,
- ‘க‘ representing ‘kha’ (aspirated) is always shown in RED color,
- ‘க‘ representing ‘ga’ (un-aspirated) is always shown in BLUE color and finally
- ‘க‘ representsing ‘gha’ (aspirated) is always shown in GREEN
We believe this presentation is much more pleasing to the eyes with no numeric characters appearing in the middle of the regular flow of the original text. To avoid using too many consonant nuktas, we also likewise followed this scheme for Hiragana language.
Known Issues: There are a few known minor issues we have come across and we will handle these in the future as and when possible.
- 5 languages (Khudawadi, Masaram Gondi, Newari, Sharada and Soyombo) use Unifont Upper Unicode font. We are looking for good language-specific, publication quality Unicode fonts from Google (Noto project) or Microsoft or individual Font designers.
- Newari and Javanese languages have some font-related issue when combining a couple of vowels with consonants. These are not TT28 issues but are certainly font-related and hence left as-is. If and when the font issues are fixed, we will re-generate and re-publish the documents.
- Whenever/wherever we see a dotted circle in the generated document, it is because the clustering of the letters is not occurring properly. We have noticed this Siddham language for the ‘i’ vowel when using the MukthamSiddham Unicode font. This is an issue with the ‘font’ and/or the underlying operating system. MukthamSiddham font has no issue in Windows 8 but has the issue mentioned above in Windows 10.
- We have not figured out how to ensure Word can recognize language-specific words and not split them across consecutive lines. We notice this issue only in documents generated for Hiragana language. Once resolved, we will re-publish the Hiragana pdf documents.
- We still need to figure out how to get multi-color text in a document’s title page and in the header area in each page.
Charts: Given below are links to TT28’s phonics super-set transliteration charts for the 28 languages. These charts were generated using the TT28 tool.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
🙏 कवितार्किकसिंहाय कल्याणगुणशालिने । श्रीमते वेङ्कटेशाय वेदान्तगुरवे नमः ॥ 🙏